[TOC]
图神经网络的核心工作是对空间域(Spatial Domain)中节点的Embedding进行卷积操作(即聚合邻居Embedding信息),然而图数据和图像数据的差别在于节点邻居个数、次序都是不定的,因此传统用于图像上的CNN模型中的卷积操作(Convolution Operator)不能直接用在图上,因此需要从频谱域(Spectral Domain)上重新定义这样的卷积操作再通过卷积定理转换回空间域上。
为了在频谱域和空间域中转换,我们借助了傅里叶公式,并且定义了图上傅里叶变换(从空间域变换到频谱域)和图上傅里叶逆变换(从频谱域回到空间域)的变换公式。具体操作是我们将节点的Embedding f(i),i∈(1,⋯,N)$f(i),i\in (1,⋯,N)$通过傅里叶正变换从空间域变换到了频谱域$\hat f$,在频谱域上和卷积核$h$进行卷积操作,再将变换后的节点Embedding通过傅里叶逆变换回到空间域,参与后续的分类等任务。
整个链路可以概括为:1. 空间域上建图,2. 谱域上卷积, 3. 空间域上进行下游任务。
对于无向图$G = (V, E)$, 定义其Laplacian矩阵为$L = D-A$,因此是一个对称矩阵。Laplacian矩阵还有如下几种拓展定义:
以上定义下的Laplacian都是实对称矩阵,因此可以进行特征分解。
Laplacian opertor $\Delta$: 拉普拉斯算子是n维欧几里德空间中的一个二阶微分算子,定义为梯度($\nabla f$)的散度:$\nabla \cdot \nabla f = \Delta f$,是笛卡尔坐标系中所有非混合二阶偏导数的和:
\[\Delta f = \sum_i^n \frac{\partial^2 f}{\partial x_i^2}\]函数f的拉普拉斯算子也是该函数的海塞矩阵的迹:
\[\Delta f = tr(H(f))\]拉普拉斯算子的物理意义是空间二阶导,准确定义是:标量梯度场中的散度,一般可用于描述物理量的流入流出。比如说在二维空间中的温度传播规律,一般可以用拉普拉斯算子来描述。
Laplacian matrix ($\mathcal L$):一种解释是,拉普拉斯矩阵的定义源于拉普拉斯算子,拉普拉斯算子是n维欧式空间中的一个二阶微分算子,当n=2时,退化为二阶平面上的边缘检测算子:
\[\Delta f(x, y) = \frac{\partial^2 f}{\partial x^2} + \frac{\partial^2 f}{\partial y^2} \\ = f(x+1, y) + f(x-1, y) + f(x, y+1) + f(x, y-1) - 4f(x, y)\]可以看出在二维空间上,拉普拉斯算子可以看作一个边缘检测算子,用来检测上下左右与自身的差异:
\[\begin{bmatrix} 0&1&0\\ 1&-4&1\\ 0&1&0\\ \end{bmatrix}\]同样,在图信号中,拉普拉斯矩阵可以用来衡量节点和周围邻居节点的差异,这里假设每个节点上的值为$x_i, i=1, …, n$。
\[L\mathbf x = (D-A)\mathbf x = (..., \sum_{v_j \in N(v_i)}(x_i - x_j), ...)^T\]进一步地,图信号的总变差(Total Variation)为:
\[\mathbf x^TL \mathbf x = \sum_{v_i} x_i\sum_{v_j \in N(v_i)}(x_i-x_j) = \sum_{(v_i, v_j) \in \mathcal E} (x_i - x_j)^2\]总变差是一个标量,它将各边上信号的差值进行加和,从而刻画了图信号整体的平滑度。
在这里矩阵的特征分解、对角化、谱分解都是同一个概念,是指将矩阵分解为由其特征值和特征向量表示的矩阵乘积的方法。只有含有n个线性无关的特征向量的n维方阵才可以进行特征分解。
Laplacian矩阵有如下性质:
证明1:行和为0显然,对矩阵求行和相当于右乘一个全1矩阵:$L\cdot \mathbf 1 = 0 \times\mathbf 1$,因此有一个特征值为0
证明2:对于任意向量$\mathbf f = [f_1, …, f_n]^T$,有:
\[\begin{aligned} \mathbf f^TL\mathbf f &= \mathbf f^TD\mathbf f - \mathbf f^TA\mathbf f \\ &= \sum_{i=1}^nd_if_i^2 - \sum_{i, j = 1}^nf_if_ja_{ij} \\ &= \frac 12( \sum_{i=1}^nd_if_i^2 - 2\sum_{i, j = 1}^nf_if_ja_{ij} + \sum_{j=1}^nd_jf_j^2) \\ &= \frac12 \sum_{i,j=1}^na_{ij}(f_i-f_j)^2 \geq 0 \end{aligned}\]因此L有n个非负的特征值
证明3:
先证明K=1时,即图G是联通的。则对于任意n阶向量$\mathbf f$,有$\mathbf f^TL\mathbf f = \frac12(\sum_{i,j=1}^na_{ij}(f_i-f_j)^2) = 0$,且$a_{ij}\geq 0$,则必有$f_i == f_j$,否则,若存在$f_i \neq f_j$,此时必有$a_{ij} = 0$,且对于其他点k,有$f_k \neq f_i$或$f_k\neq f_j$ ,则点按照取值划分等价类至少可以划分成两类,且两类点之间没有边相连,这与图G是一个连通图矛盾。
再证明$K > 1$时,此时L是分块对角矩阵(K块),构造向量$\mathbf e_1 = [1,…, 1, 0, …], \mathbf e_2 = [0,…,0,1,…1,0,…], … \mathbf e_k=[0,…0,1, …, 1]$,这K个向量线性无关且都是L关于特征值0的特征向量,得证。
性质4可由L是实对称矩阵推出。实对称矩阵具有性质1:实对称矩阵属于不同特征值的特征向量正交;2:对于n阶实对称矩阵L,存在正交矩阵使得$L = U\Lambda U^T$,其中U是由L的特征向量组成的矩阵。
性质4说明了拉普拉斯矩阵具有如下分解
\[L = U\Lambda U^{-1} = U\Lambda U^T\]对于归一化的laplacian,有:$\mathbf f^TL\mathbf f = \frac12(\sum_{i,j=1}^na_{ij}(\frac{f_i}{\sqrt{d_i}}-\frac{f_j}{\sqrt{d_j}})^2)$,$\lambda$为$L$的特征值,对应的特征向量为$\mathbf u$ $\Leftrightarrow$ $\lambda$为$L_{sys}$的特征值,对应的特征向量为$D^{\frac12}\mathbf u$
对于随机游走的laplacian:有:$\mathbf f^TL\mathbf f = \frac12(\sum_{i,j=1}^na_{ij}(\frac{f_i}{\sqrt{d_i}}-f_j)^2)$,$\lambda$为$L$的特征值,对应的特征向量为$\mathbf u$ $\Leftrightarrow$ $L\mathbf u = \lambda D\mathbf u$
$L^{sys}$和$L^{rw}$都有与L类似的性质。
傅里叶变换的定义:
\[F(w) = \mathcal F[f(t)] = \int f(t)e^{-iwt}dt \\ F(w) = \mathcal F[f(t)] = \sum_{t=1}^{N}f(t)e^{-iwt}\]即时域上信号$f(t)$与基函数$e^{-iwt}$的积分,其中基函数满足$\nabla^2 e^{-iwt} = -w^2e^{-iwt}$。经典傅里叶变换有如下规律:傅里叶变换的基函数是拉普拉斯算子的本征函数。类比于广义特征值,可以将$e^{-iwt}$看作$\nabla^2$的特征向量。因此,找到图的laplacian matrix的特征向量,就找到了谱域上的基函数。
图上的傅里叶变化可以定义为:
\[F(\lambda_l) = \hat f( \lambda_l) = \sum_{i=1}^N f(i)u_l(i)\]其中$u_l(i)$为特征值$\lambda_l$对应的特征向量的第i个分量。写成矩阵的形式有:
\[\begin{pmatrix} \hat f(\lambda_1)\\ \hat f(\lambda_2) \\ \vdots \\ \hat f(\lambda_N) \end{pmatrix} = \begin{pmatrix} u_1(1)& \cdots& u_1(N)\\ u_2(1)& \cdots& u_2(N) \\ \vdots& \ddots& \vdots \\ u_N(1)& \cdots& u_N(N) \end{pmatrix} \begin{pmatrix} f(1)\\ f(2) \\ \vdots \\ f(N) \end{pmatrix}\]写成矩阵形式即:
\[F = U^Tf\]因此,给出点的embedding,左乘特征向量构成的矩阵的转置,即可得到经傅里叶变换得到的节点embedding $\hat f$。注意,是一个图(一个Laplacian)对应一个谱域,谱域的基函数是laplacian的特征向量,任何想转化到这个图的谱域上的函数,都要左乘$U^T$
傅里叶变换:
\[\mathcal F^{-1}[F(w)] = \frac{1}{2\pi}\int F(w)e^{iwt}dw \\ f(i) = \sum_{l=1}^N\hat f(\lambda_l)u_l(i)\]这里由于L是实矩阵,特征向量是实向量,共轭后还是自身。
推广到图上,写成矩阵形式:
\[\begin{pmatrix} f(1) \\ f(2) \\ \vdots \\ f(N) \end{pmatrix} = \begin{pmatrix} u_1(1) & u_2(1) & \cdots & u_N(1)\\ u_1(2) & u_2(2) & \cdots & u_N(2)\\ \vdots & \vdots & \ddots & \vdots\\ u_1(N) & u_2(N) & \cdots & u_N(N) \end{pmatrix} \begin{pmatrix} \hat f(\lambda_1)\\ \hat f(\lambda_2) \\ \vdots \\ \hat f(\lambda_N) \end{pmatrix}\]即:
\[f = U\hat f\]卷积定理:
\[f(t)\star h(t) = \mathcal F^{-1}[\hat f(w)\hat h(w)] = \frac{1}{2\pi}\int \hat f(w)\hat h(w) e^{iwt} dw\]公式中h是一个卷积核。
推广到图上,给定图上的卷积核$h$(在谱域上是一个对角矩阵,对各频率分量进行增减,因此有$U^Th = diag(\lambda)$)
\[(h\star f)_G = U[(U^T h)(U^T f)]\]其中,卷积核在谱域上:$\hat h = U^T h = diag(\hat h(\lambda_i) ), i = 1, …,n$
因此有:
\[(h\star f)_G = Udiag(\hat h(\lambda))U^T f\]图上的机器学习任务实际上是找到一个合适的卷积核,适用于目标任务,更直接的,是找到对角线上的N个自由参数的取值。
存在的问题:
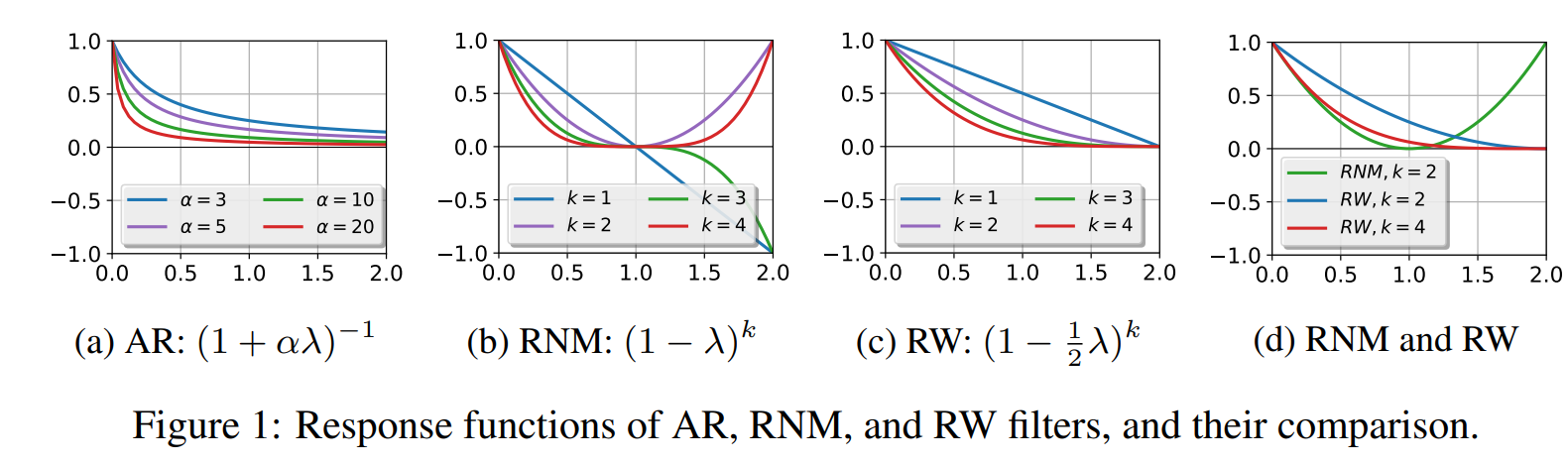
为防止过拟合,提出一种多项式filter:
\[g_\theta(\Lambda) = \sum_{k=0}^{K-1}\theta_k\Lambda^k\]即有:
\[g_\theta(\Lambda) = \begin{pmatrix} \sum_{k=0}^{K-1}\theta_k\lambda_1^k & &\\ & \ddots & \\ & & \sum_{k=0}^{K-1}\theta_k\lambda_n^k \end{pmatrix}\]因此可简化为:
\[y_{out} = \sigma(Ug_\theta(\Lambda)U^Tx) = \sigma(\sum_{k=0}^{K-1}\theta_kU\Lambda^kU^Tx) = \sigma(\sum_{k=0}^{K-1}\theta_kL^kx)\]上式最后一个等号使用了实对称矩阵必可进行相似对角化的性质。
通过K阶多项式,将图上的卷积限定在了K近邻,优点有:
但是,仍需要计算矩阵乘法(计算$L^k$)
提出一种用Chebyshev多项式(常用于近似,Chebyshev可用于多项式插值,能最大限度的降低龙格现象,并提供多项式在连续函数的最佳一致逼近)近似卷积核的方法,可以用来降低卷积运算的复杂度(上一篇论文中也有提到)
\[g_\theta(\Lambda) \approx \sum_{k=0}^{K-1}\theta_kT_k(\hat \Lambda)\]$\theta_k$是Chebyshev多项式的系数,$T_k(\hat \Lambda)$是取$\hat \Lambda = \frac{2\Lambda}{\lambda_{max}}-I$($\in [-1, 1]$)的Chebyshev多项式.
Chebyshev多项式是递归定义的:
\[T_k(\hat\Lambda) = 2\hat\Lambda T_{k-1}(\hat \Lambda)-T_{k-2}(\hat \Lambda) \\ T_0(\hat \Lambda) = I, T_1(\hat \Lambda)=\hat \Lambda\]因此我们无需计算矩阵乘法,递推Chebyshev的复杂度为$O(n^2)$,因此计算$g_\theta$的复杂度为$O(Kn^2)$,此时谱图卷积式子:
\[y_{out} = \sigma(Ug_\theta U^Tx) = \sigma(\sum_{k=0}^{K-1}\theta_kT_k(\hat L)x)\]在GCN模型中,作者首先做了额外的两个假设:$λ_{max}≈2,K=1$,这两个假设可以大大简化模型。而作者希望假设造成的误差可以通过神经网络参数训练过程来自动适应。此时:
\[Ug_\theta U^Tx = \theta_0x + \theta_1(L-I)x = \theta_0x+\theta_1(D^{-\frac12}AD^{-\frac12})x\]令$\theta = \theta_0 = -\theta_1$,则有:
\[Ug_\theta U^Tx \approx \theta(I+D^{-\frac12}AD^{-\frac12})x\]这样一个卷积核只有1个参数
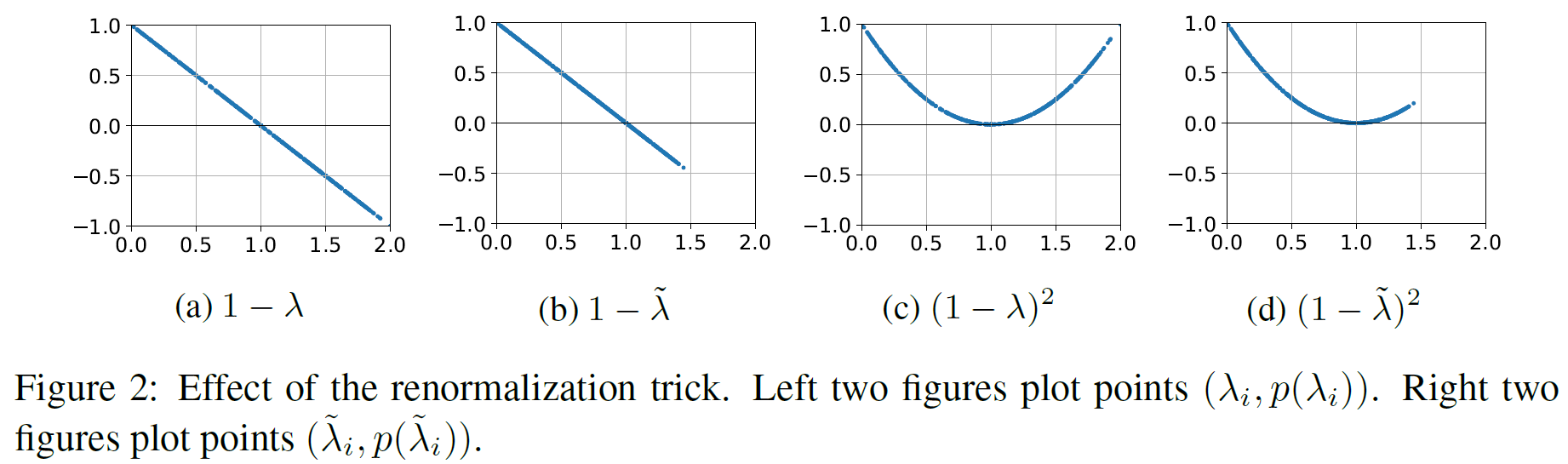
此时$I+D^{-\frac12}AD^{-\frac12}$的特征值在$[0, 2]$之间,多层传播会导致数值不稳定和梯度消失、梯度爆炸的现象,因此本文提出了再正则化(renormalization trick):
\[I+D^{-\frac12}AD^{-\frac12} \rightarrow \hat D^{-\frac12}\hat A\hat D^{-\frac12} \\ \hat A = A+I, \hat D_{ii} = \sum_j \hat A_{ij}\]输入节点矩阵$X \in \mathbb R^{N\times C}$, C是节点向量的维数,有F个filters:
\[Y = \sigma(D^{-\frac12}\hat A\hat D^{-\frac12}X\Theta)\]$\Theta \in \mathbb R^{C \times F}$是filter参数矩阵,$Y \in \mathbb R^{N \times F}$是卷积后的节点矩阵。复杂度为$O(NFC)$
从图信号处理的角度:
根据 The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains ,拉普拉斯矩阵的特征值$\Phi = (\phi_1, …, \phi_n)$和特征向量$\Lambda = diag(\lambda_1, …, \lambda_n)$分别扮演着频率(frequency)和傅里叶基(Fourier basis)的作用。
图信号(graph signal)是一个在图上节点上定义的实值函数$f: \mathcal V \to \mathbb R$,在谱域空间中(以傅里叶基为基地),一个图信号$\mathbf f = (f(v_1), …, f(v_n))^T$,可以被分解为:
\[\mathbf f = \Phi \mathbf c,\]其中$\mathbf c = (c_1, …, c_n)^T$,$c_i$是$\phi_i$的参数。这一步和上文里<逆变换:从谱域到空间域>中公式$\mathbf f = U \mathbf {\hat f}$等价。
图滤波器(graph filter)被定义为是一个矩阵$G \in \mathbb R^{n\times n}$,根据 Discrete Signal Processing on Graphs : G是线性平移不变的(linear shift-invariant),当且仅当存在函数$p(\cdot): \mathbb R \to \mathbb R$,使得$G = \Phi p(\Lambda)\Phi^{-1}$. 其中,$p(\Lambda) = diag(p(\lambda_1, …, \lambda_n))$。这个函数被称为G的频率响应函数(frequency response function)。
这个定义也解释了为什么前文<图上卷积>中的式子($(h\star f)_G = Udiag(\hat h(\lambda))U^T f$,其中$Udiag(\hat h(\lambda))U^T$可看做是滤波器,$\hat h()$可以看作是对应的频率响应函数)。
当信号用基函数的线性组合表示时,基函数的系数较小,则这个信号越平滑。对于第i个基函数来说,“平滑程度”可以看作是相邻点之间函数值的差距:
\[\sum_{(v_j, v_k) \in \mathcal E} w_{jk}[\phi_i(j) - \phi_i(k)]^2 = \phi_i^TL\phi_i = \lambda_i\]因此,一个平滑的信号应当具有更多的低频分量,即,将一个信号表示为傅里叶基的线性组合时,较大的$\lambda_i$对应的基$\phi_i$的平滑程度越低(即不平滑),此时,如果我们希望平滑图信号,则经过图滤波器后的图信号:
\[\mathbf {\hat f} = G\mathbf f = \Phi p(\Lambda)\Phi^{-1}\Phi\mathbf c \\ = \Phi p(\Lambda)\mathbf c \\ = \sum_{i}^np(\lambda_i)c_i\phi_i\]因此,对于较大的$\lambda_i$,$p(\lambda_i)$应当较小,反之亦然。
从这个角度,考察GCN:
GCN中,认为图卷积$I+D^{-\frac12}AD^{-\frac12}$的特征值在$[0,2)$,多层传播会造成问题,因此利用了 re-normalization 技术,将图卷积变为$\hat D^{-\frac12}\hat A \hat D^{-\frac12}$,则有:
\[\hat D^{-\frac12}\hat A \hat D^{-\frac12} = I - \hat D^{-\frac12}\hat L \hat D^{-\frac12}\]将$\hat L$进行谱分解,则有:
\[\hat D^{-\frac12}\hat L \hat D^{-\frac12} = \Phi \hat \Lambda \Phi^{-1} \\ I - \hat D^{-\frac12}\hat L \hat D^{-\frac12} = \Phi (I-\hat \Lambda)\Phi^{-1}\]此时,这个滤波器的频率响应函数为$p(\hat \lambda_i) = 1-\hat \lambda_i$
这个函数是线性低通的,它对特征值在$[0,2]$(实际上特征值的取值范围达不到2)内的分量有抑制作用。但是,可以看到他对待靠近0和靠近2的特征值是等同的,即这个fiter对高频分量没有良好的抑制作用。
但是也有研究表明,由于图具有一定的异质性,滤波器保留一定的高频分量是有利的,这可能是RNM filter在实际中不比RW之类的差的原因吧。
于是我们可以解释以下问题:
谱域卷积的缺点:
图卷积神经网络笔记——第三章:空域图卷积介绍(1)_Ma Sizhou-CSDN博客_基于空域的图卷积
[1706.02216] Inductive Representation Learning on Large Graphs (arxiv.org)
graphSAGE是为了解决现实中无法将完整的图数据一次放入内存或显存的问题以及无法获得完整图结构的问题。
GraphSAGE是inductive的,训练时只保留训练集的边,利用已知节点的信息为未知节点生成embedding,GraphSAGE 取自 Graph SAmple and aggreGatE,指将邻居采样,并聚合。

其中,K是aggregator的数量,也是权重举矩阵的数量(每一层聚合器和权重矩阵都是共享的),也是网络的层数(聚合K-hop邻域内的信息)
GraphSAGE中的采样:对每个节点采同样个数的邻居样本,以形成minibatch,对于采样个数大于点的度数的情况,采用放回抽入以获得足够的邻居样本。
聚合器采用了Mean Aggregator、Pool Aggregator、LSTM Aggregator。实验上Mean aggregator效果最好,LSTM 需要进行诸如乱序处理将有序模型变为无序模型。
参数学习:对于有监督的任务,可以使用每个节点pred和true的交叉熵作为损失函数;无监督时,可设计如下损失函数:
\[J_G(\mathbf z_u) = -\log(\sigma(\mathbf z_u^T\mathbf z_v)) - Q\mathbb E_{v_n \sim P_n(v)}\log(\sigma(-\mathbf z_u^T\mathbf z_v))\]该损失函数由两部分组成,第一项是使邻居点相似,第二项是使非邻居节点相异(负采样)
目前主要有三种注意力机制算法,它们分别是:学习注意力权重(Learn attention weights),基于相似性的注意力(Similarity-based attention),注意力引导的随机游走(Attention-guided walk)。这三种注意力机制都可以用来生成邻居的相对重要性。
节点j对节点i的注意力权重:
\[\alpha_{i,j} = \frac{\exp{(LeakyReLU(\mathbf a [W_{x_i}||W_{x_j}]))}}{\sum_{k \in N(i)}\exp{(LeakyReLU(\mathbf a [W_{x_i}||W_{x_k}]))}}\]$\mathbf a, \mathbf W$分别是可学习得参数向量和参数矩阵.
$|$表示拼接.
直接通过节点得向量表示计算相似性
\[\alpha_{i,j} = \frac{\exp({\beta cos(W_{x_i}, W_{x_j})})}{\sum_{k \in N(i)}\exp{(\beta cos(W_{x_i}, W_{x_k}))}}\]$\beta$是一个可学习得bias,$W$是一个可训练的参数矩阵。
以Lee et al. 2018 作为例子:
GAM方法在输入图进行一系列的随机游走,并且通过RNN对已访问节点进行编码,构建子图embedding。时间t的RNN隐藏状态 $h_t∈R_h$ 编码了随机游走中 $1,⋯,t$ 步访问到的节点。然后,注意力机制被定义为函数 $f^′:R_h→R_k$,用于将输入的隐向量$f′(h_t)=r_{t+1}$映射到一个k维向量中,可以通过比较这k维向量每一维的数值确定下一步需要优先游走到哪种类型的节点(假设一共有k种节点类型)。